加州大学圣地亚哥大学医学院、史丹福健康照护、威斯康辛州大学医院等三个医疗体系,将于4月至5月期间先行试验,用聊天机器人ChatGPT读取病患在网上的提问,然为医师草拟回复。三家医疗机构藉此了解人工智慧(AI)能帮助医院人员看病时间的节省多少,AI表现的同感共情心(empathetic),医患之间供求的精确和准确程度等。
据华尔街日报(WJS)报道,加州大学圣地亚哥大学医学院医师Marlene Millen 已经利用电邮收件进行了约一周的ChatGPT测试,她表示,AI最开始生成的回复需要大量编修,她和测试团队成员正帮忙改进机器人的回答。Millen 现在点开病患来讯时,ChatGPT立即根据电邮来件内容与病患病历摘要,草拟出回复,但同时遵守联邦隐私法规,保护病患资料。
4月稍早就展开试验的圣蒂亚哥与威斯康辛两个医疗体系,现在都限制AI辅助回复治疗建议。威斯康辛大学医院初步只让ChatGPT协助回应开处方笺、文书申请这类问题。
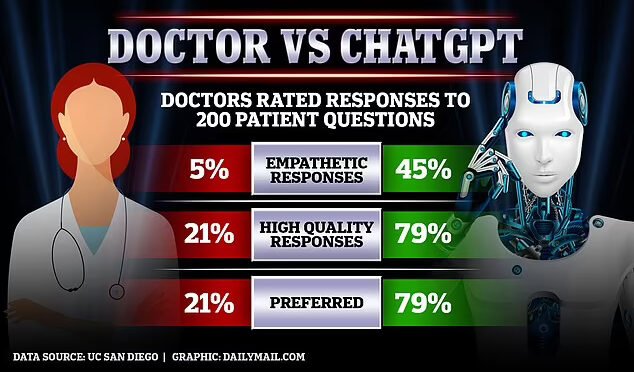
美国医学会杂志(JAMA)内科医学期刊28日刊出的最新研究则呈先出一些有趣的发现。在回答病患网路提问时,ChatGPT得分比真人医师还高。这项研究是让一组医师“盲测”,在不知道是谁回答的情况下,为列出的答复评分。ChatGPT得到“很好”、“非常好”评分是真人医师的四倍。而回复是否具有同感共情心?只有4.6%的真人医师回答被评为“具有”或“很有”,ChatGPT 则有45%。
之前已有报道称,研究发现,ChatGPT能提供了更高质量的答案,比真正的医生更有同感共情心。
加州大学圣地亚哥分校的一项研究将医生和ChatGPT的书面回复与现实世界的健康服务进行了比较,以确定哪一个最受欢迎。
一个由医疗保健专业人员组成的专家小组表示更喜欢ChatGPT给予了79%的回复,并在提供的信息和更多的理解方面给予了更高的质量评价。具体确定让ChatGPT给哪些方面的回复,专家们仍在做进一步论证中。
来源:华尔街日报等。
(美国华文网编发)